

Data Platforms in 2030
Data Platforms in 2030
Turning the database "right-side-out"?

Spoiler alert: I’m not a psychic and don’t have a time machine, so I can’t really say what the data platforms will look like in 5-7 years. But I’ve been noticing some trends that are hard to ignore, so I wanted to make a prediction or two. Maybe there is also a bit of a wish list from me here 🙂
Status Quo
The current way of building large-scale data processing architectures hasn’t changed much since Martin Kleppmann’s famous Turning the database inside-out talk in 2014:
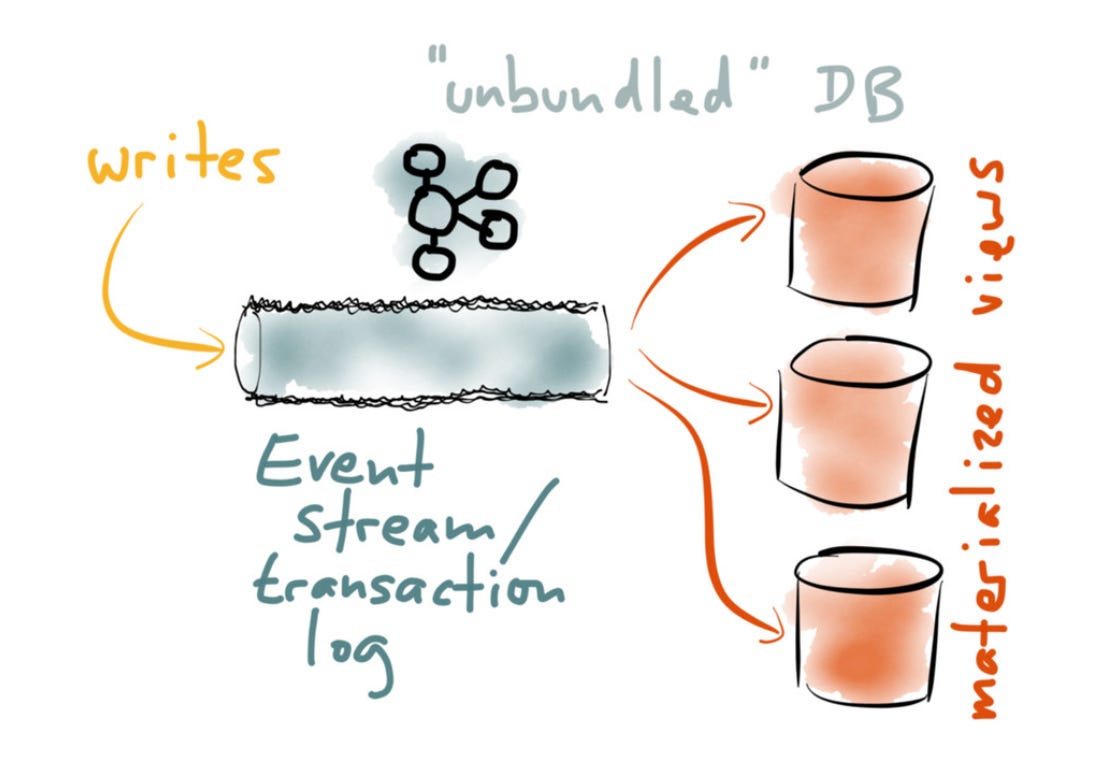
We still use Apache Kafka or similar technologies as a log for capturing events and then maintain a set of connectors for writing data to destinations like a data lake, a data warehouse, an OLAP database, a search index, a cache, etc. All of this is glued together with batch and/or streaming transformations.
This has been working… fine. But I think we can do much better.
Why Change?
So, what’s so wrong with the status quo that I’m hoping for a different architecture in 2030?
Data pipelines now power many user-facing systems, including ML / “AI” use cases. For a while, this has been implemented only by Big Tech companies, but not anymore. When it comes to “AI”, I’m not even talking about LLMs, but features like recommendations, personalization, etc.
Despite what you may think, latency is not a primary concern, in my opinion. You can get very far by doing micro-batching. There are far bigger issues.
Modern Data Platforms Are Too Complex
Even if you use a lot of off-the-shelf solutions. Even if you commit to a certain vendor. In 2023, we still don’t have a data platform packaged as a single tool. For example, Redpanda allows you to start a broker, a schema registry and an HTTP proxy from a single binary. Postgres, with a few extensions, can do pretty much anything, and it’s also just a single binary. But there is no end-to-end data platform solution! I’ve recently seen this diagram on LinkedIn with a commentary that it looked very simple:

Does it look simple to you?
Of course, modern data platforms need to do many things: data ingestion, processing, storage, querying, governance, etc. But so do modern databases! I think one of the reasons we don’t have a data platform as a tool is that large companies that have the resources to build it keep evolving their existing platforms, by creating or adopting new tools to cover a certain part of the system. There is no need to rewrite the whole thing from scratch.
Eventual Consistency Is Not Good Enough
Think about how many destinations a domain event from Kafka can be written to:
A data lake or a lakehouse to power analytical and ML use cases.
An OLAP database to power user-facing analytics.
A search index or a cache or transactional database to power some application features.
Another Kafka topic after a real-time ETL process.
And so on (3rd party systems, legacy systems, webhooks, feature stores, etc.)
Each destination requires its own connector that can fail, start lagging, emit duplicates. It’s possible that an event arrives to an OLAP database within 5 seconds, arrives to the data lake within 10 minutes, but fails to arrive to another Kafka topic because the partition is offline 🙈.
And even if we target a single datastore, e.g., a data warehouse, it’s very likely that each table may receive events from the same business transaction with different delays. E.g. a checkout in an e-commerce website may result in writes to many tables: orders, sales, users, etc. When using a CDC process to ingest data into a data warehouse, we rarely have any guarantees that all writes from the same transaction will arrive simultaneously. It means you always have to account for eventual consistency when using data. This is problematic for internal analytics, but this can be devastating for user-facing applications!
There are some solutions. Materialize guarantees internal consistency, but it can’t provide guarantees for external systems. Google’s Napa paper introduces the concept of a queryable timestamp that can be used as a watermark for queries, but like with any watermark solution, it means the need to wait for the slowest record.
Cloud-Native Architectures Are Underutilized
Many existing data platform technologies were designed many years ago when the Cloud was young. My favourite new explanation about why you should design systems in a cloud-native way is written by the folks behind WarpStream. You can eliminate quite a bit of complexity, and achieve better performance, scalability and resiliency. Of course, there is always a price to pay, but I feel like it’s a pretty good trade-off.
Separation of compute and storage (primarily in the form of an object store like S3) can be considered mainstream nowadays, but what about true elasticity with autoscaling? Automation that just works?
New Architecture (?)
If the current technological wave resulted in turning the database “inside out” and comprising a data platform from a log and many independent purpose-oriented databases, the next wave seems to attempt a reverse move, turning the database “right-side-out”. This means a consolidated platform that’s simultaneously good at a few very different things and packaged as a single tool. Here’s what I see:
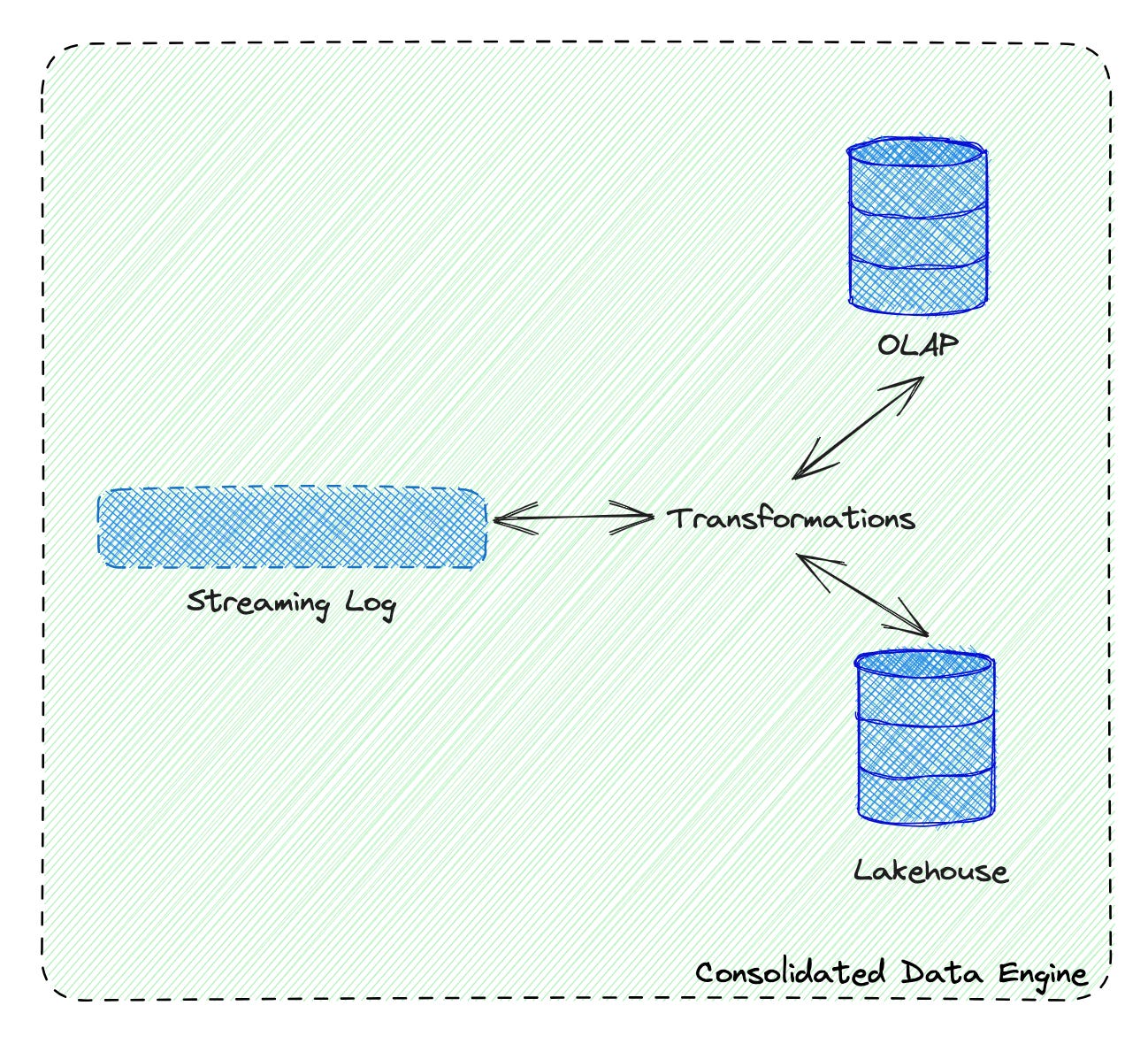
A streaming log, a lakehouse and an OLAP engine meshed together into a single consolidated data engine.
Why these three components? I believe that by combining them, you get a minimum viable data platform: it handles data ingestion, long-term storage (which can be used for ad-hoc querying and ML), and an analytical database, which can be used for internal, as well as external analytics and user-facing features.
It would support three tiers of datasets:
“transient”, AKA Kafka topics with limited retention.
“standard”, data is persisted to a Lakehouse location after being ingested from the log.
“queryable”, data is persisted to an OLAP engine after being ingested from the log.
(Sorry, I don’t have better names for these yet…)
All writes to the streaming log happen transactionally with the writes to other storage engines. This is a very important distinction compared with the existing systems. This completely eliminates eventual consistency and guarantees read-after-write consistency, at a minimum. Of course, it’s also a trade-off, and sometimes, you’d be willing to trade consistency for latency. If you think that it means slow distributed transactions, keep reading.
Finally, there is no need to differentiate stream and batch processing. There is just “processing” 🙂. A unified engine (based on SQL, of course) can be adaptable:
If a dataset is available in the “transient” tier only, use streaming mode.
If a dataset is available in the “transient” and “lakehouse” tiers and an operation requires historical processing, it should use historical data in the “lakehouse” tier first for an efficient backfill and then switch to the “transient” tier for the edge processing. Kinda like Apache Flink’s Hybrid Source.
I don’t think we’ll end up with a single binary for this, but it should be possible to package everything as a single tool. And because everything is tightly integrated, adding first-class support for observability, data lineage and data governance should be quite straightforward. We’ll also need a central data catalog / schema registry and a single execution platform (but these could be pluggable).
It’s Already Happening
In fact, this consolidation trend is already happening:
Redpanda has announced support for Iceberg protocol for its tiered storage, so we can get Streaming Log + Lakehouse. Btw, WarpStream announced the same. Confluent’s turn?
Streaming databases like Materialize, RisingWave and Timeplus combine Streaming Engines with powerful databases (materialized views don’t necessarily imply OLAP-like performance, but it’s not that far to get there).
Apache Arrow has a thriving ecosystem of tools that use the same fast columnar format. Apache Arrow DataFusion and Apache Arrow Ballista implement powerful data processing frameworks that can compete with Apache Spark. Arrow Flight is an Arrow-native RPC layer. Combine all of this, and we can get a Processing Engine (batch only at the moment) + Lakehouse (e.g. via Iceberg) + OLAP (e.g. via Arrow Flight SQL or ADBC or DataFusion or something else).
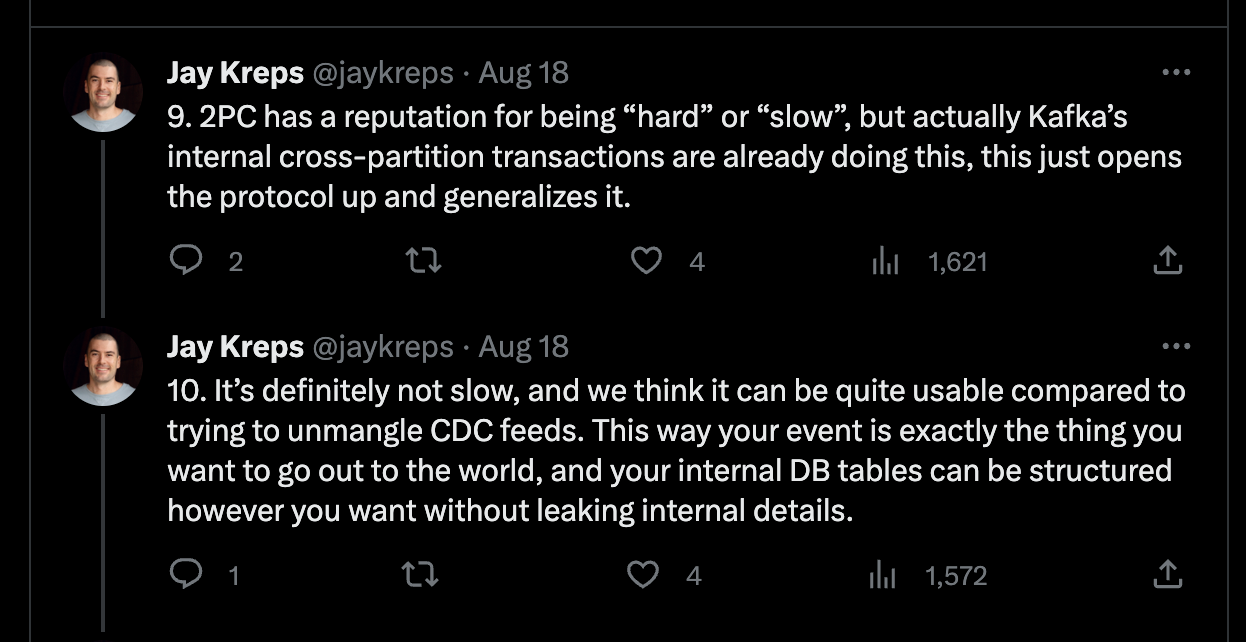
Apache Kafka community has recently announced a proposal to support participation in a two-phase commit protocol, which goes beyond the existing transactional guarantees. I think it may be proposed for better interop with Apache Flink, but it also aligns nicely with the architecture I described. So we can support Streaming Log + Lakehouse or Streaming Log + OLAP use cases (or both) simply by implementing this proposal. You may think that 2PC is a terrible idea, but Jay Kreps disagrees with you:
2PC is not the only possible solution; there is some new research into using a distributed MVCC approach for providing transactional guarantees between different datastores (unfortunately, this does affect write performance quite a bit).
Apache Paimon is probably the closest project to the architecture I described. It has a unified storage engine that supports both Lakehouse and OLAP use cases and integrates really well with a Streaming Log like Apache Kafka. It’d benefit a lot from Kafka’s 2PC!

Do We Have a Winner?
Out of all the technologies I mentioned, I’m really bullish on streaming databases and the Apache Arrow ecosystem. Streaming databases already have a transactional boundary (they’re databases, duh). And Apache Arrow is just so promising as a format (columnar! no serialization/deserialization cost! vectorized queries!) with a great, rapidly growing ecosystem. Kafka 2PC is one more requirement.
But I wouldn’t be surprised to see a completely new solution. The Great Resignation helps. Ultimately, it took a year or so to prototype WarpStream or Restate.
Unexpected Discovery
If you explore the new projects I mentioned, you’ll notice that almost none of them use JVM languages. Most are implemented in Rust or C++. One of these languages (guess which one I’m betting on) will probably be required in a data engineer’s toolbox by 2030.
Thanks to Alexander Gallego, Filip Yonov and Matt Helm for sharing their thoughts on the topic.
What is used to make this image? https://substackcdn.com/image/fetch/f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fe02e2326-ab77-4e80-bec9-2ad36676a7a6_749x472.jpeg
How about the importance of open source moving forward?