


My Biggest Issue With Apache Flink: State Is a Black Box
And what can be done about it?

I’ve been using Apache Flink for many years, and inspecting / manipulating the state is still the most challenging thing by far.
In runtime, the state is kept in an embedded RocksDB database (assuming you use the RocksDB backend; but it’s the most popular and obvious choice), which is distributed across many nodes - good luck collecting and decoding all data.
You can work with a savepoint instead, but it’s just a collection of binary blobs without any remote resemblance of a schema to read them. Of course, you can try using State Processor API, but it’s also very opposite of user-friendly. Unfortunately, it requires reconstructing some parts of the topology to be able to access state variables - they must have the same UIDs and types. This is also applicable to any state variables used by Flink operators. So, if you want to access the state of a join, you need to study the source code first and understand how that join is implemented 😭.
For several reasons (and I guess performance is one of the key ones here) state is just a black box. Should it be this way? And are there any alternatives?
But Why?
But first of all, why do I care so much about manipulating the state? Why not just let the framework handle it?
Well, I wish it was that simple. The state is ubiquitous in Flink. Even if you have a stateless “Kafka → Flink → Kafka” pipeline that performs some lightweight transformations like projections and filtering, you still use the state for tracking the message offsets for the Kafka source. Sometimes, it’s very convenient to modify those - e.g. when performing some kind of migration.
But also, inspecting state is extremely useful when debugging stateful transformations. E.g., your left join may be producing the null values you don’t expect, so checking the join state directly will tell you a lot about the state of a computation.
Finally, state evolution is still painful. State Processor API is a recommendation here, but, as I mentioned, it’s really hard to use.
Queryable State
Queryable state is one way to expose the internal state. You typically choose what state variables should be exposed, and the data becomes available over some endpoint. Sounds handy, right? It’s probably not something you’d expose to your end users, but it can be used for observability and tooling. It may not make it much easier to manipulate the state, but at least it’d be easier to inspect.
However, it’s now deprecated in Flink: the latest Flink documentation (1.19) does not even mention it. I don’t really know why; the mailing list claimed the lack of maintainers as a reason, but it doesn’t feel like a strong justification.
In comparison, queryable state seems to be flourishing in the Kafka Streams ecosystem (called “interactive queries”). Here’s a recent KIP, for example.
What About Spark?
Databricks has recently announced State Reader API, which is very similar to Flink’s State Processor API. However, it addresses the developer experience by separately exposing state metadata.

So, it completely eliminates any guessing or reconstructing parts of your application just to understand what state variables to access. Which is all I’m asking.
It doesn’t look like it has made it to vanilla Apache Spark yet, but I hope it’ll make it there via a community contribution eventually.
Flink would benefit from a similar approach as well.
State Observability
If you can’t easily manipulate the state in Flink, can you at least see what’s there, perhaps with a third-party tool? Datorios is a new observability tool exactly for that. It can show you the state of a given window quite easily, and you can zoom in and zoom out to find a specific window.
It’d be great to easily explore the state of any operator in the topology (including custom sources and sinks). I hope it’ll be supported eventually.
Streaming Database: Just Another Table?
What do you do in this case if you’re a streaming database? Expose the state as a set of tables, of course.
RisingWave shared a great post describing the usage of internal tables for storing state data. I think it’s quite an elegant solution fully embracing the database spirit.
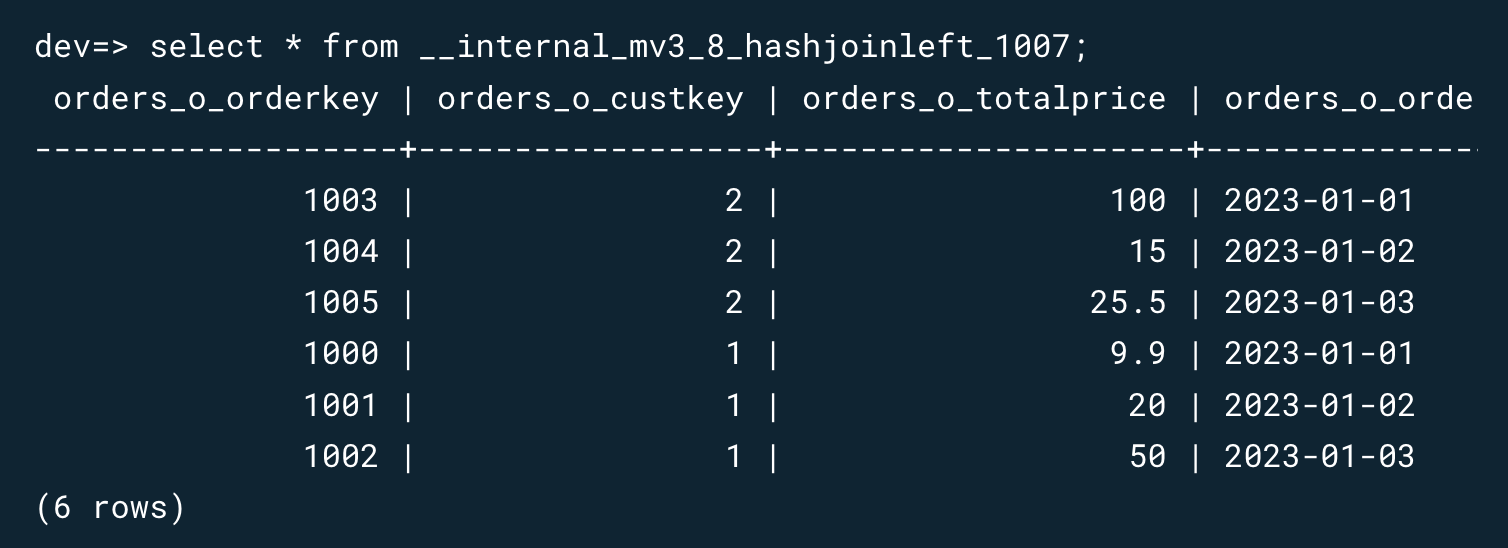
I didn’t have a chance to use it, but I think it’s a solid pattern I’d love to see adopted by other streaming databases as well.
We Need More State Backends
Currently, Flink only supports two state backends: HashMapStateBackend and EmbeddedRocksDBStateBackend. HashMapStateBackend can be used in production, but it comes with many gotchas (of course, it’s primarily limited by the available memory).
There are several proprietary state backends implemented by Flink vendors (Ververica, Confluent), but as far as I know, they’re also based on RocksDB.
There is a FlinkNDB paper covering an alternative state backend, but I haven’t seen any adoption of that.
I believe we can benefit from more diverse state backends.
For example, imagine a Postgres state backend. Yes, it wouldn’t be suitable for large or extremely demanding workloads, but most small and medium ones may work. There are plenty of modern cloud databases that support large, high-performance workloads. Do you know that AWS RDS Aurora Postgres supports table sizes up to 32 TiB?!
And how convenient would it be to modify a row in a Postgres table to change Kafka source offsets?! Don’t need to deal with savepoints or RocksDB at all. We’d need to have a mechanism to support concurrent access, but in the worst-case scenario, the workflow may look like this:
Stop the job
Modify the state by updating the rows in Postgres
Resume the job
Still, it is much, much better than using State Processor API.
If you think that the state storage must be embedded and local, Google Cloud Dataflow is a good counter-example. Dataflow used to store its state in Bigtable, a NoSQL database (maybe it still does, but it’s been a while since I used it). This was possible because Bigtable scales really well, has low latency, and Dataflow employed efficient batching to interact with it.
Instead of a Summary
Making stream processing easier also means making state inspection and manipulation easier. This is a really hard problem to solve. I hope that vendors will realize this and offer solutions that actually work. Not everyone needs extreme scale, and good developer experience is as important.
Spark’s State reader is also open sourced - you can give a try with Spark 4.0 beta. Databricks provides the functionality slightly earlier than the Apache Spark, not only to have advantages but also to cope with different release cadence.
Recommended to have a look at Hazelcast Stream Processing. It is an IMDG (state-in-memory) with added stream processing capabilities. Super fast stream joins. Solves the problem in one solution. Can keep all your enriching data in-memory if you can afford. Or alternatively keep the hot data in cache and overflow on to a more persistent data store.
Flink is stream processing with state storage externalized.