


State and Timers
It's all you need.

Stateful stream processing is a complicated topic. Windowing. Streaming joins. Late-arriving data and watermarks. Sessionization. Streaming analytics… It’s hard to say where to start.
But a few years ago, I started mentoring an engineer. They had foundational knowledge about stream processing, knew a lot about Kafka, and used Kafka Streams. But they wanted to understand better what’s possible to achieve with stateful stream processing and how exactly it works.
I started planning our sessions… And I realized that you really need to understand only two basic building blocks: state and timers.
State
Your business logic needs to have access to some kind of state.
You can think about it as an in-memory variable available to you (the APIs make it this easy), but internally, it’s backed by resilient, scalable, distributed storage. Modern stream-processing systems typically use RocksDB as a state backend.
There are different types of state:
Keyed vs “global”. Typically, you access the state in the context of a certain key, e.g. a user id, a product id, a wallet, etc. This requires performing a shuffle in order to route all records with the same key to the same “worker”. “Global” state is not frequently used, but you should still consider using it in some rare use cases, I wrote about it here.
Key-value, List, Map, even versioned/timestamped - there are different flavours of state APIs that optimize for different access patterns.
Timers
Timers are as important as state. Because streaming systems work with unbounded datasets, a concept of windowing is used to control the state size.
I do firmly believe that there is a place for windowless stateful stream processing, especially in the context of streaming joins. I covered more in the blog post I already mentioned.
Defining windows is the primary application of timers (more on this below). However, when using stream processing engines to build applications (or “microservices”), timers can also be used as a helpful mechanism to perform an action later (sort of a scheduled callback).
Timers heavily depend, well, on time 🙂. There are different notions of time we need to account for: event time, ingestion time, and processing time. Event time is the most useful one, but it also requires the use of mechanisms to handle data that’s out of order, arrived late, etc. This can get very complicated very quickly.
Putting It Together
Let’s implement a very basic, naive tumbling window that we’ll use to aggregate values.
Imagine we’re building a Top 10 sold products dashboard for an e-commerce website. We’ll use a tumbling window of an hour. Assuming we have a simple key-value state and a timer as building blocks, the whole algorithm looks like this:
Key all input records (“product sold” events) using the product id.
Implement a keyed processing function (executing in the context of a single key):
Start a timer for the end of the hour (we’re using processing time, which doesn’t account for a lot of edge cases, but it’s good enough for this example).
Keep incrementing the value of the state variable for each product record processed.
When the timer fires at the end of the hour:
Emit the accumulated result from the state.
Reset state value to 0.
Start another timer for the next hour!
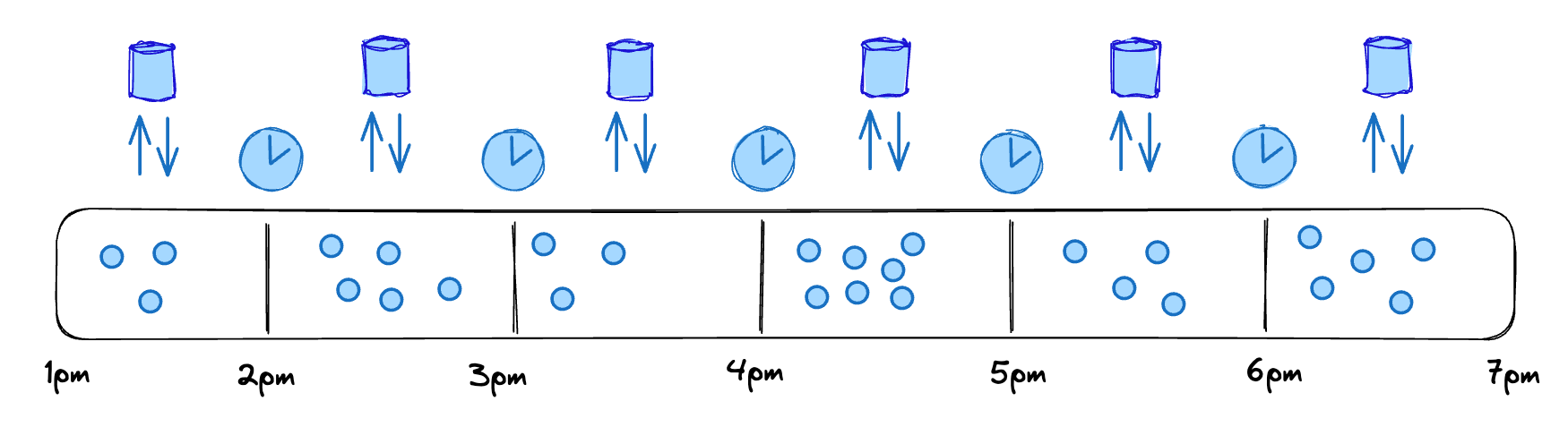
Of course, the real tumbling window implementation is more complicated than this, but it’s pretty close conceptually.
I hope this was enough to understand these basic, but foundational building blocks. If you want to learn more, I recommend reading:
Streaming 101 and Streaming 102 by Tyler Akidau.
Timely (and Stateful) Processing with Apache Beam by Kenneth Knowles.
Stateful Stream Processing and Timely Stream Processing from Apache Flink docs.