

Considerations for Data Stream Materialization
Considerations for Data Stream Materialization
To materialize or not to materialize 🤔

When you’re just starting your data streaming journey, you may have a few Kafka topics, some simple processing logic and a data destination to start. Maybe you just need to ingest data into your data lake / lakehouse and perform some lightweight filtering and transformations.
Eventually, with more and more use cases, you start adding branches in your logic, new transformations, new data destinations, etc.
And this is where you need to make an important decision: should I materialize the results of a given transformation by writing them to a new Kafka1 topic? The alternative data exchange approach is direct message passing in case of intermediate transformations and direct writes to data destinations / sinks.
This may seem like a simple decision. But, without much thinking, this can lead to huge cost and performance implications.
Let’s go over a concrete example:
We ingest several Change Data Capture (CDC) data streams from an operational database. These streams are captured as Kafka topics; let’s call them “raw”.
These streams contain PII data, as well as columns with BLOB data.
We’d like to write these streams to an Iceberg data lake for ML workloads. We do NOT want to write PII data as is (it should be pseudonymized), but we need BLOB columns.
We need to write these streams to Elasticsearch for powering user-facing search. We don’t need PII or BLOB data here.
We also want to build a stream-processing service for fraud detection. This service needs to consume a data stream with order information, and it requires PII data.
Finally, we have another stream-processing service that performs streaming analytics and writes results to a key-value database. This service doesn’t need PII or BLOB data.
How do you architect this? Want to take a break and think about it? 🙂
Materialized vs Direct Message Passing
To start, let’s consider all possible data transformations we need to perform:
raw.$name → pseudonymized.$name for handling PII.
raw.$name → noblob.$name (please propose a better name) for removing BLOB data.
raw.$name → aggregated.$name for analytics.
Wait, maybe it should be pseudonymized.$name → aggregated.$name? Great question! There are many options to consider.
On one side, we can model all transformations within a single monolithic stream-processing job. E.g. an Apache Flink job ingesting several CDC topics, performing filtering, fraud detection, analytics, and writing results to Iceberg and triggering notifications. This is where we utilize direct message passing between nodes in the topology. Note: “direct“ doesn’t mean in-memory; sometimes, a network shuffle would be required. In this scenario, we create 0 new Kafka topics.
On the other side, we can model all transformations as separate stream-processing jobs with Kafka topics storing intermediate results. We have a job for handling PII data and writing results to another topic. We have a job for dropping BLOB data and writing results to another topic. Fraud detection is a separate job that consumes a raw topic. So is a streaming analytics job, which emits new topics with aggregated data. Finally, we have a job for consuming anonymized data and writing results to Iceberg. Similarly, for Elasticsearch and key-value databases. In this scenario, we could easily create 4-5 x N topics (where N is the number of entities).
But also, we can have anything in between and choose only to create some topics. So, how do you make a decision on which approach to use?
Cost vs Performance vs Reusability: Choose Two
You’ll have to decide between a cost-efficient, performant or reusable system. It’s possible to have two out of three, but rarely all three.
If you choose to be cost-efficient and performant, you need to rely on direct message passing, which means no “intermediate topics” → hard to reuse anything. If you want reusability and performance, you end up with beefy topics and appropriately tuned clients, which adds additional load to the Kafka cluster, which makes it more expensive. And if you need reusability and cost-efficiency, you still need to create topics, but you’ll tweak the topic configuration and the clients to avoid cluster load (e.g. very aggressive batching, very short retention, etc.), which makes it harder to achieve low latency, for example.
Some guidelines:
Each new topic increases your bill, so you’d want to avoid creating them unnecessarily. Topic retention can be reduced significantly (to just a few hours) to save on resources, but then it requires maintaining SLAs and strong SRE practices.
Things can get very expensive at scale. Especially if you early decide to materialize everything by default, you’ll be surprised to realize all your input data is increased 2x, 3x or more when it comes to Kafka writes.
Whenever a data stream is consumed by multiple consumers, you should consider materializing it as a topic. Especially if the transformation is non-trivial (stateful or involves external IO).
Generally, direct message passing is more performant than materializing data to a topic and consuming it: you avoid a lot of network IO, multiple rounds of serialization and deserialization.
There are some rare exceptions to this rule, e.g. a stateful stream-processing job that’s heavily backpressured on sink writes could benefit from a Kafka topic as a very fast sink instead (with a separate stateless job writing to the slow sink after reading from Kafka). This definitely requires lots of testing.
Not All Technologies Are Equally Flexible
Apache Flink can support both styles of data exchange quite well. It has a battle-tested Kafka connector and many built-in and open-source source and sink connectors for various datastores. Adding a custom connector is fairly straightforward.
Kafka Streams framework was specifically designed to use Kafka topics as inputs and outputs (with Kafka Connect handling connectors), so it naturally leans towards topic materialization. Another example is Materialize, which doesn’t support many sinks.
So, if you need to use a particular technology, understand whether it leans towards topic materialization. This could be a great starting point for assessing the overall design.
My Solution
Here’s how I’d design the system based on the earlier requirements:
I’d definitely materialize pseudonymized data streams as topics (pseudonymized.$name). It’s usually a heavy transformation that can be compute-intensive and/or involve external IO.
I’d model the fraud detection service as a separate job that just consumes raw topics.
I’d also model the streaming analytics service as a separate job that consumes pseudonymized topics and writes to the key-value database directly. There is not much value in materializing aggregated results at the moment.
Iceberg and Elasticsearch writers would be separate jobs, too, primarily because they’d need to be scaled and tuned differently. The Iceberg sink job would consume pseudonymized topics, and the same for the Elasticsearch sink one: even though these topics contain BLOB data, dropping it is a relatively cheap stateless transformation.
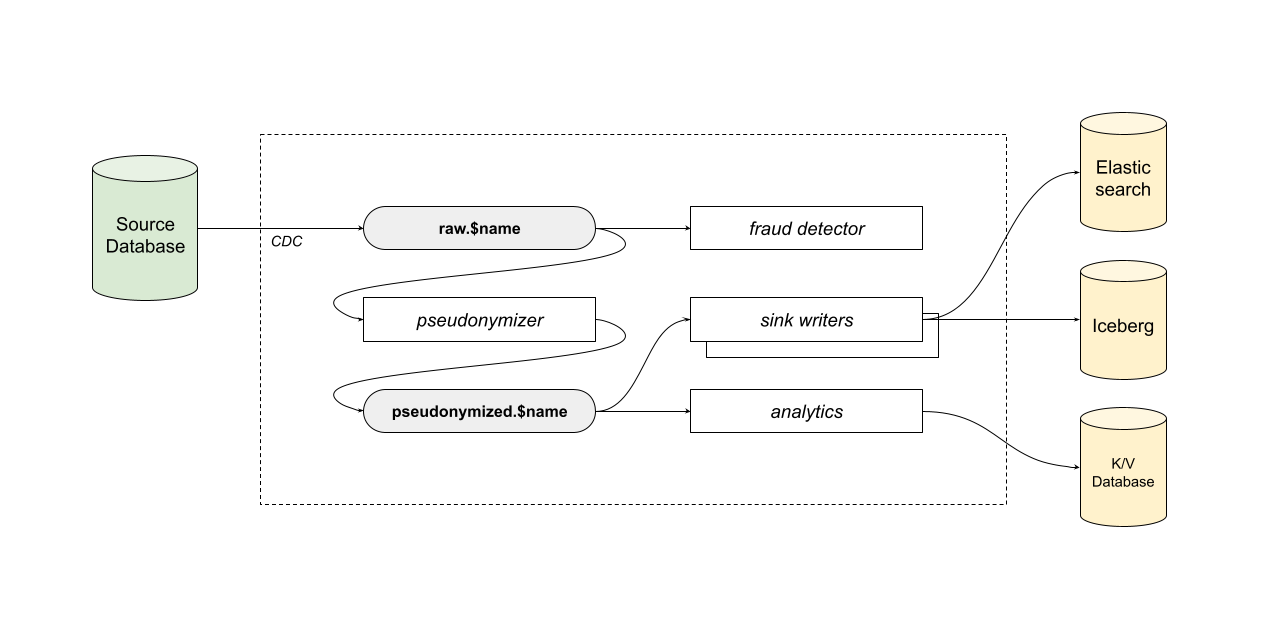
So, in the end, you can see I preferred to minimize the number of materialized topics. I don’t see much value in creating many topics given the current requirements, and I feel like adding new topics is always easier than removing the existing ones.
Instead of a Summary
I hope this was useful! I don’t see this topic being frequently discussed, but it can make a huge impact on the overall system design, especially in the current market conditions favouring cost-efficient solutions. If you want to learn more about designing efficient data streams, check some of my other posts: Approaches for Defining Message Metadata and Changelog vs Append-Only Data Streams.
This is not Kafka-specific; the same question can be asked about any streaming platform.